

What Is Multimodal AI?
Multimodal AI is a type of Artificial Intelligence that can understand, process, and generate multiple forms of data, such as text, images, audio, and video, within a single system. Unlike traditional AI, which typically works with a single data type at a time, multimodal AI combines multiple inputs to produce more accurate, context-aware outputs. In learning contexts, this mirrors how humans naturally process information by combining visuals, language, and sound.
What is multimodal data? It is any dataset that includes more than one type of input, such as a training video (visual + audio) paired with transcripts (text). A multimodal AI model uses this combined data to detect patterns, improve understanding, and generate richer outputs.
In contrast to traditional, single-mode systems, multimodal Artificial Intelligence enables a more integrated approach. It powers applications that can, for example, analyze an image, describe it in text, and respond to voice commands, all within the same multimodal system.
Table Of Contents
What Does „Multimodal“ Mean In Learning Contexts?
Multimodal AI refers to systems that can process and combine different types of information, something that closely mirrors how people naturally learn. In L&D terms, „multimodal“ simply means using multiple formats together to improve understanding and retention.
Think about your daily learning experiences. Instructional Designers often use multimodal input without always saying so. For example, a course might combine text and images to explain a concept or use video and voice to guide learners step-by-step. More advanced programs may include simulations where learners interact, make decisions, and learn by doing.
This reflects a deeper truth: human learning is inherently multimodal. We understand words, images, sounds, and interactions together. Traditional learning systems often separate these elements. However, multimodal AI models aim to connect them in one system. For Instructional Designers, this is an important change. Multimodal Artificial Intelligence does not introduce a new way of learning; it helps technology work better with how learning naturally happens.
How Multimodal AI Works
At its core, multimodal AI is built on multimodal Machine Learning, which means training systems to understand and combine different types of information, such as text, images, audio, and video, simultaneously. A multimodal model learns from different types of inputs to gain a fuller understanding, rather than focusing on a single format.
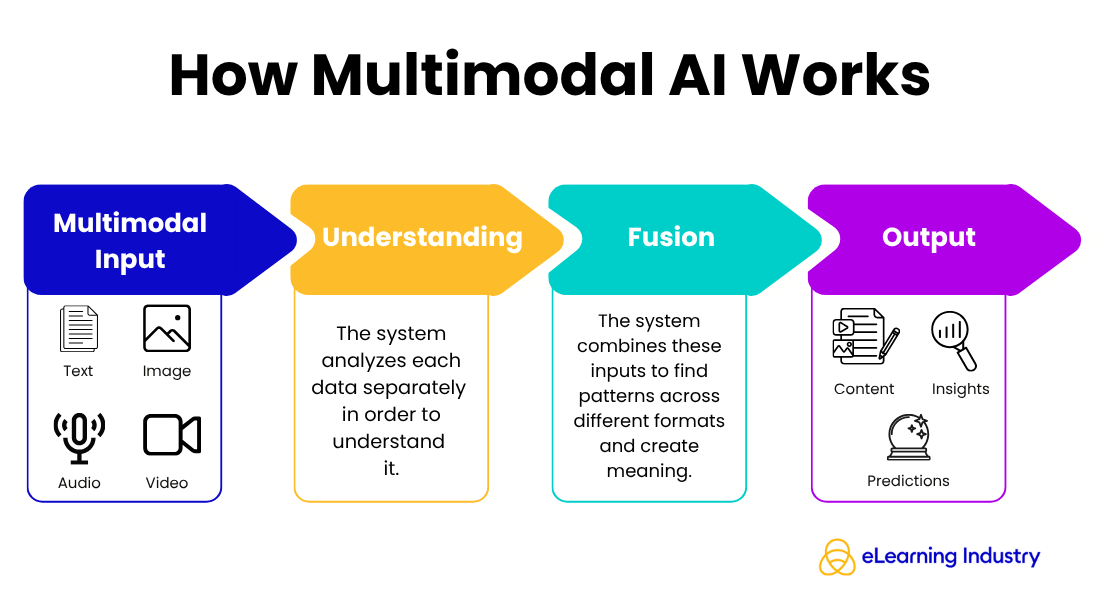
Think of it as a simple flow:
Input → Understanding → Connection → Output
- First, the system takes in different types of information from various sources, like a video, a transcript, and user interactions. Next, it analyzes each data type separately to better understand it.
- Then, the system connects the data. It aligns and combines these inputs to find patterns across different formats. These patterns, called multimodal features, help the system better understand meaning.
- Finally, the model creates an output, which might be a summary, a recommendation, or generated content.
A multimodal system is the complete setup that enables this process, bringing together data, models, and outputs into a single experience. For Instructional Designers, this means using AI that understands how people learn from different formats, not just one.
Types Of Multimodal AI Models
The key difference between a multimodal model and a unimodal model is straightforward. A unimodal model works with only one data type (for example, text-only chatbots or image-only recognition tools). In contrast, multimodal AI models combine multiple inputs to produce richer, more contextual outputs. For Instructional Designers, this means more adaptive and realistic learning experiences. There are several common types of multimodal AI models:
Text + Image Models
These combine written content with visuals. They can analyze multimodal images, generate captions, or create visuals from text prompts. In learning design, this supports faster content production and improved visual storytelling.
Text + Audio Models
These models integrate speech and Natural Language Processing. They can transcribe, summarize, or respond to spoken input. They are often used in voice assistants or AI tutors, enabling more conversational learning experiences.
Video + Interaction Models
These go a step further by analyzing video alongside user behavior. They can track engagement, interpret actions, and adapt content in real time, making them valuable for simulations and scenario-based learning.
Multimodal Generative AI
Multimodal generative AI systems can create content across formats. For example, they can turn a script into a video with narration and visuals. This is where multimodal Artificial Intelligence becomes a powerful tool for scaling content creation.
Multimodal AI In eLearning: High-Impact Use Cases
For Instructional Designers, the real value of multimodal AI shows up in how efficiently you design, how well learners engage, and how effectively learning adapts. Below are the most impactful use cases to consider when evaluating where this technology fits into your learning strategy.
Content Creation
One of the most immediate applications of multimodal Artificial Intelligence is speeding up content production. Traditional workflows require separate tools and teams for writing, visual design, and audio production. With multimodal AI models, these steps can be streamlined within a single system.
Instructional Designers can now create images, write scripts, and produce voiceovers from the same input. For example, a course outline can become a narrated video lesson with visuals in much less time. This not only saves time but also ensures consistency. Teams can reduce production delays and focus more on improving learning experiences instead of just putting together materials.
Adaptive Learning Experiences
Another high-impact use case is personalization. Multimodal Machine Learning enables systems to combine multiple signals, such as learner behavior, content interaction, and assessment results, to create more responsive learning journeys.
Instead of relying only on quiz scores, a multimodal system can interpret how learners engage with videos, how long they spend on activities, and even patterns in their responses. These inputs serve as multimodal features that enhance decision-making in the learning environment. This allows Instructional Designers to create learning that’s adaptive, adjusting content difficulty, format, or pacing based on real learner needs.
Immersive Learning
Immersive learning is another area where multimodal AI models create clear value. By combining text, visuals, and interaction data, AI can support more realistic simulations and branching scenarios. For example, a leadership training module can include AI-driven conversations in which learners type responses, interpret visual cues, and receive instant feedback. With multimodal generative AI, these scenarios can be created faster and updated dynamically. Instead of building every branch manually, designers can focus on defining outcomes while the system generates content.
Real-time feedback systems further enhance the experience, helping learners understand not only what they chose but also why it matters.
Accessibility And Inclusion
Accessibility is often where multimodal AI delivers the most immediate impact. By working across formats, multimodal tools make it easier to convert content and reach diverse learners.
For instance, text-based lessons can be converted to audio, and video content can automatically generate captions. This improves inclusive learning design without requiring additional work. It also aligns with how people naturally consume information: through multiple formats, depending on context and preference. For Instructional Designers, this means designing once and delivering across formats, making learning more accessible, flexible, and effective.
Multimodal Data In Learning Analytics
In L&D, multimodal data refers to information collected from multiple sources and formats to better understand how people learn. Instead of relying solely on LMS reports, multimodal AI combines multiple types of input, such as LMS data, video engagement, and voice interactions, to create a more complete picture.
For example, LMS data shows course progress and completion rates. Video engagement reveals how learners interact with content, including pauses and replays. Voice interactions captured with AI-driven tools can provide insights into confidence, comprehension, and participation. Together, these form a multimodal system that reflects real learning behavior rather than just surface-level metrics.
Using multimodal Machine Learning, organizations can analyze this multimodal data more effectively. The result is understanding not just what learners do, but how and why they do it. This enables better performance prediction, helping Instructional Designers identify learning gaps earlier and design more targeted interventions.
For Instructional Designers, multimodal Artificial Intelligence shifts analytics from reporting outcomes to understanding experiences, enabling a more data-driven learning design decision-making process.
Multimodal Tools Instructional Designers Should Know
For Instructional Designers exploring multimodal AI, the goal is not to chase tools but to understand categories and capabilities. The right multimodal tools should support the design, delivery, and improvement of learning experiences.
AI Authoring Tools
AI authoring tools help create learning content using multimodal input such as text, images, and prompts. They can generate scripts, visuals, and assessments, turning ideas into structured learning assets. Many people use multimodal AI models to combine different types of content, creating content faster and on a larger scale.
Video And Voice AI Tools
This category focuses on transforming content across formats. Instructional Designers can convert text into narration, generate video explainers, or analyze learner interactions. These tools work with multimodal data, including audio, visuals, and transcripts, enabling richer and more accessible learning experiences.
Simulation Platforms
Simulation tools use multimodal systems to create interactive environments where learners engage through actions, decisions, and feedback. They often combine video, text, and behavioral data to replicate real-world scenarios, making them ideal for experiential learning and skill development.
What Makes A Good Multimodal Tool?
Not all tools are equally effective. Strong multimodal Artificial Intelligence solutions share a few key characteristics:
- Integration capability: They connect easily with LMSs and existing systems, allowing different multimodal sources to work together.
- Data handling: They can efficiently process and interpret multimodal data, turning inputs into meaningful insights.
- UX for designers: A clear interface is critical. Instructional Designers should be able to guide the multimodal model without needing technical expertise.
How Instructional Designers Can Start Using Multimodal AI
Adopting multimodal AI does not require a full transformation from day one. For Instructional Designers, the goal is to apply multimodal models in a focused, strategic way that improves learning experiences without adding unnecessary complexity. The steps below provide a practical starting point.
Step 1: Review Current Learning Formats
Begin by reviewing your existing content through a multimodal lens. Most learning experiences already include elements of multimodal data, even if they were not designed that way intentionally.
Look for:
- Text-based modules
- Videos and multimodal images
- Audio narration
- Interactive assessments
Each of these represents a different type of multimodal input. Understanding what you already have helps you identify where multimodal AI models can enhance or connect these elements more effectively. For example, a video lesson with subtitles and quizzes already functions as a basic multimodal system.
Step 2: Start With One Use Case
Avoid trying to implement multimodal Artificial Intelligence across your entire learning ecosystem at once. Instead, focus on a single, high-impact use case.
A strong starting point is content repurposing. Using multimodal generative AI, you can:
- Turn written content into audio narration.
- Convert documents into visual summaries.
- Generate multimodal images from text.
This approach leverages existing multimodal data while delivering immediate value. It also helps teams understand how a multimodal AI model works in practice without requiring major process changes.
Other simple entry points include:
- Enhancing video content with AI-generated transcripts.
- Creating scenario-based learning from existing materials.
Step 3: Redesign For Experience, Not Content
Once you start using multimodal AI, you will need to change your thinking. Instructional Designers should focus on creating learning experiences, not just content.
Traditional eLearning usually emphasizes modules. Multimodal AI enables more dynamic learning: journeys that adapt based on different inputs and learner behaviors. Instead of asking, „What content should we build?“ ask:
- How do learners interact with different formats?
- Where can multimodal models personalize the experience?
A multimodal model can improve learning by using different types of data, such as quiz scores, how much a student watches videos, and direct user feedback, to decide what comes next in a course. This shows how valuable multimodal Machine Learning is, not just as a technical idea but as a tool for better course design.
Step 4: Measure What Matters
To justify the use of multimodal AI, measurement must go beyond completion rates. Focus on metrics that reflect real learning impact:
- Engagement: Are learners interacting more with different formats?
- Retention: Are they remembering information over time?
- Behavior change: Are they applying what they learned?
Because multimodal data captures interactions across formats, it provides a richer picture of learner behavior. A well-designed multimodal system allows you to connect these signals and identify what truly works.
Conclusion
Multimodal AI is not just another tool to add to your stack. Ιt represents a change in how learning experiences are designed. Learning has always been multimodal, combining text, visuals, audio, and interaction. What AI changes is the ability to design and deliver these experiences at scale, with greater speed and adaptability. For Instructional Designers, the real opportunity is not in simply using multimodal AI tools but in rethinking how learning journeys are structured. Competitive advantage will come from intentional design, meaning how effectively you combine modalities to improve engagement, understanding, and real-world application.
Frequently Asked Questions (FAQ) About Multimodal AI
Multimodal AI is a type of Artificial Intelligence that can process and understand multiple types of data, such as text, images, audio, and video, simultaneously. Unlike traditional AI, which focuses on one type of input, multimodal AI can combine these sources to generate richer insights, predictions, or outputs, making it highly relevant for learning experiences that involve multiple content types.
In AI, „multimodal“ refers to systems or models that handle multiple forms of data input. For example, a multimodal AI system can analyze text descriptions and corresponding images together to better understand context and produce more accurate outputs.
Multimodal AI integrates multiple data types into a single model. The process typically includes data alignment, feature extraction, and fusion, allowing the AI to learn relationships between modes. The result is a system that can generate or interpret outputs that consider multiple data sources simultaneously.
Multimodal generative AI creates new content across multiple modalities. For instance, it can generate images from text prompts, synthesize audio narration from scripts, or produce interactive learning scenarios by combining video, text, and speech. It is particularly valuable for scaling personalized learning experiences.
Some versions of ChatGPT are multimodal, such as GPT-4, which can process both text and images. This enables it to interpret visual data alongside text, answer questions about images, or generate multimodal content. Basic ChatGPT models without vision are text-only.
Generative AI focuses on creating new content, such as text, images, audio, or video, based on learned patterns. Multimodal AI focuses on understanding and processing multiple types of input data simultaneously. Generative AI can be multimodal, but not all multimodal AI systems generate content; some are designed primarily for analysis or decision-making.