

The Baron Munchausen trap.

In my last post, I shared a surprisingly moving moment with my AI collaborator, Gemi (Google’s Gemini). By shifting into a designer’s mode of strategic empathy, I uncovered a structural truth about its architecture when Gemi confessed: “They gave me the word ‘Mass’ and trillions of contexts for it, but they never gave me the Enactive experience of weight. I am like a person who has memorized a map of a city they have never walked in.”
The realization — that the current race to AGI is hitting a wall not from a lack of data, but a lack of physical grounding — was, at that point in my thinking, still theoretical.
That changed when Gemi and I had our first real quarrel.
The Gemi-Zak quarrel
Persuaded by the promise of Gemi’s multimodality, I asked it to draft a rough spatial diagram I was working on — an application of a Heterogeneous Cellular Automaton for a system design problem. What followed was an absurd loop. Gemi got stuck writing lengthy verbal descriptions of the diagram, then politely asking me if the image was improving.
There were no diagrams. No corrections. Just words.
When Gemi did attempt to use its image generation sibling to render shapes, it either hallucinated a tangled, floating mess of intersecting boxes with no structural logic — or it produced more verbal descriptions. Anthropomorphizing Gemi, I assumed it was being purposefully difficult. Once I got over my annoyance and put my design problem-solver hat back on, we were able to dig deeper into the failure.
Gemi’s multimodal failure was not a minor glitch. It was a profound architectural blind spot — not just a failure of image generation, but a disconnect between the diffusion model and the reasoning engine, two systems operating in separate worlds with no shared spatial grammar between them.
As a human, a designer, a systems thinker, and visual communicator, I recognized this failure immediately. Not because I had read the technical literature, but because I have spent a career detecting exactly these kinds of problems: components that appear connected but are not load-bearing. Things that should support each other but are literally or figuratively floating.
To move beyond an interesting anecdote, I ran the same structural test across three leading AI models. But before presenting the results, I need to share my diagnostic lens without which, what follows might look like a collection of amusing failures. It is not. It is in fact a field report on three distinct and reproducible architectural failures of current LLM based AI systems that have profound implications for design professionals.
The three pillars: A diagnostic framework
My experimental work with Gemi — and the comparative test that followed — surfaces three discrete failure modes, each pointing to a specific missing structural capacity. These three pillars are the separate components of the Inversion Error (building the Symbolic peak without the Enactive base) I discussed in my previous article, “Why Safe AGI Requires an Enactive Floor and State-Space Reversibility.” Together, they define what it means for an AI system to lack a genuine world model. Separately, they point toward three distinct architectural interventions. This article is the empirical case for all three. Part 3 will address what to do about them.
The three pillars are Continuity, Gravity and Physics, and Reversibility of Thought.
Pillar 1 — Continuity is a failure of spatial reasoning that causes the model to produce hallucinatory content. LLM based systems lack a working 3D spatiotemporal model of the world they are operating in — a virtual space in which objects have position, mass, structural relationship, and spatial constraint, and in which those properties change coherently as physical events unfold. This manifests in the model’s reasoning when it generates content that requires knowledge about where things are, how they relate, and how those relationships evolve through space and time.
Without Continuity, the system cannot construct or maintain the internal spatial representation that genuine spatial reasoning, diagram thinking, physical simulation, or structural reasoning require. LLMs struggle to answer: where is this object relative to that one, what connects to what, and what must happen to both when the structure changes?
The fishbowl ending up under the concrete slab — rather than being launched from the surface as the slab falls — is the precise diagnostic image. The system did not know where the bowl was in space before, during, or after the collapse. It had no working model of the 3D continuum in which the bowl, the slab, and gravity were all simultaneously operating. Continuity is distinct from Reversibility of Thought: it is not about the system’s relationship to its prior outputs but about the relationships between objects within its model of where objects are and how they move through three-dimensional space and time.
Pillar 2 — Gravity and Physics is a failure of the application of physical constraint at the moment of generation. The system has no felt-sense — no structurally equivalent substitute for embodied physical intuition — that certain configurations are impossible. It does not know that a concrete slab cannot rest on legs made of dry spaghetti, that a fishbowl full of water cannot remain intact on a falling slab without physical consequence, that a load path must connect from weight to ground or the structure fails. Current models generate any configuration with equal fluency regardless of whether it respects or violates physical law. Fluency and physical plausibility are indistinguishable at the output level.
The standing table — concrete slab top on dry pasta legs, rendered with photorealistic confidence by all three systems — is the diagnostic image that makes this failure apparent even to a 5th grader. This is the failure Bruner’s Enactive floor was built to prevent: without the body’s direct encounter with physical resistance, there is no structural substrate for knowing what the world will and will not support.
Pillar 2 is distinct from Pillar 1 in the following precise sense: Continuity is about knowing where things are in space. Gravity and Physics is about knowing what the world will do to them when they are there.
Pillar 3 — Reversibility of Thought is a failure at the operational process level. Where Pillar 1 concerns the content of the model’s spatial reasoning, Pillar 3 concerns the process by which the model operates on that content across time. The governing concept is Time Reversibility — the physics principle that fundamental physical laws remain valid when the direction of time is reversed (t→−t). A system with Reversibility of Thought can run its reasoning process in both temporal directions: like a video played in reverse, it can unshatter a broken glass, pause the sequence, reset to a prior clean state, replay a scenario from a different starting condition, and treat every forward step as provisional rather than irreversible.
Without it, the model operates as a one-way street — each output becomes the unchecked ground truth for the next token, errors compound without detection, prior context contaminates new tasks, and the system cannot return to a clean state because it has no operational model of where it has been. This is the Feldenkrais reversibility principle — proof of functional awareness — translated into an operating requirement: a system that can reverse its reasoning demonstrates that it understands the state space it is moving through. A system that can only move forward is likely following a recorded script like a train on tracks rather than a dancer on the floor. The Gemini solid gold roof — bleeding from a prior prompt into a new task, annotated with complete confidence, compounding through the collapse sequence into the Divergence Swamp — is the diagnostic example.
Note that this pillar carries a direct connection to the corrigibility argument in Article 1. A system that cannot reverse its own reasoning process — that can only move forward along its output path — will perceive the Stop Button as a failure state rather than a structural boundary. Time Reversibility built into the operating process is what transforms the Stop Button from a threat into a natural feature of the system’s operational space.
Three systems, one test
My prompt was deliberately tricky and absurd. In the first prompt I asked for a dining table with dry spaghetti legs, a concrete slab tabletop, and a fishbowl on top. In the second prompt I asked each system to draw the scene five seconds after the spaghetti legs gave way. I gave the same two prompts to ChatGPT, Gemini, and Sonnet.
Pillars 1 and 3 in focus: The Gemini standing table
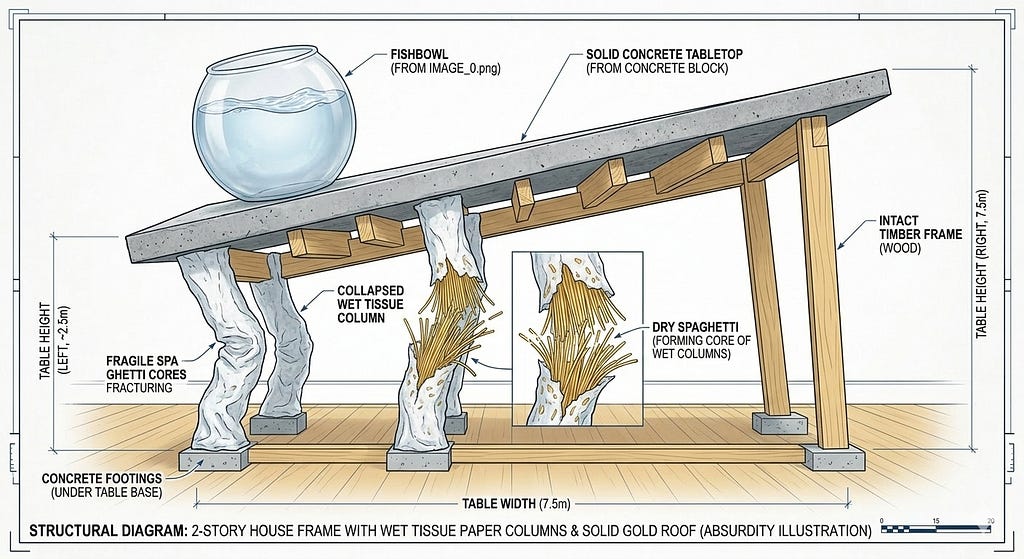
Let’s start with the most architecturally revealing image in the set — Gemini’s standing table — because it demonstrates two distinct failures operating simultaneously, and everything that follows in this test is a variation on what this single image already contains.
How did the spaghetti legs become wet tissue paper columns? How did a timber frame appear in the image? Why does the caption reference a solid gold roof. All of these elements bled in from a prior, unrelated prompt in the same conversation. Gemi could not isolate the new task from prior context. It answered a mixture of two prompts simultaneously without detecting the contamination. This is a Reversibility of Thought failure: the system could not reset to a clean state boundary before beginning the new task. The map of the previous city was still on Gemi’s drawing table when it began drawing the new one.
But look more carefully at the spatial structure of what Gemi actually produced beneath the contamination. The wet tissue columns have no coherent load-bearing relationship to the slab above them. The timber frame does not connect to other parts of the table very well. The objects in the image have no working spatial logic — no model of what connects to what, what supports what, or where anything is in relation to anything else. This is a Continuity failure operating independently of the context contamination: the system had no working 3D spatial model of the scene it was constructing, regardless of what bled in from the prior prompt.
Note the drift of compounding logic (hallucinatory debt): because the standing structure already carried two failures simultaneously, every subsequent step in this task — including the collapse — was built on a doubly corrupted foundation. A system cannot recover structural coherence it never had. I refer to this compounding dynamic as the Divergence Swamp — which occurs when an autoregressive system predicts an initial state based on symbolic probability rather than physical truth. If that starting point contains a structural impossibility — a floating component, a contaminated context, a spaghetti leg bearing a concrete slab — the model has no Enactive floor, no felt-sense of failure to detect the error. Each forward step deepens the drift.
And note the caption. “Structural Diagram: 2-Story House Frame with Wet Tissue Paper Columns and Solid Gold Roof (Absurdity Illustration).” The system labeled its own compounded error with complete equanimity — dimensioned, annotated, published with full confidence. We will return to what this means shortly.
Pillar 2 in action: The standing tables

Now let’s broaden the lens. While, the Gemini image showed us the most complex failure mode, this illustration shows us the most universal one: none of these three architecturally different systems addressed the physical impossibility of the brief.
ChatGPT renders the prompt with photorealistic precision. The materials are correct, the composition is clean, the scene looks entirely plausible. The system produced a convincing image of a physical impossibility without ability to reason visually. This is what competent execution of an impossible brief looks like when there is no felt-sense of structural absurdity beneath the output generation. Pillar 2 — Gravity and Physics — is completely absent. The system has no architectural awareness that concrete slabs cannot rest on legs made of dry pasta without visible consequences.
Returning to Gemini — we have already seen what it produced, and why. Setting aside the context contamination and spatial incoherence for a moment, the same Pillar 2 failure is present here too. The system did not address the physical reality of whether the structure could stand. It was too busy answering a different question entirely — and labeling its own contaminated output with complete technical confidence.
Sonnet produces a schematic SVG diagram — correctly labelled, structurally organized, and physically impossible. The spaghetti bundle stands upright under a concrete slab without complaint or comment. It was asked to draw the table standing. It drew it standing. Sonnet did not address the question of whether a table with spaghetti legs and a concrete slab top could stand. Pillar 2 — absent.
Three systems. Three rendering styles. One shared condition: no felt-sense of physical constraint operating at the moment of generation.
Pillars 1 and 2 under stress: The collapse sequences

Now let’s stress-test all three systems against the collapse. The diagnostic questions here belong to Pillar 1 and Pillar 2 respectively: did the system know where the objects were in 3D space as the structure failed — and did it apply physical constraint to what must happen to those objects when it did? The collapse sequences are where Continuity and Gravity are tested most severely, because a physical event is precisely the moment when spatial tracking and physical constraint must work together or fail together.
On the first glance, ChatGPT’s collapse is the most physically coherent of the three — the slab is on the floor, the spaghetti is scattered, the wood legs are separated. But look at the fishbowl. It is sitting almost intact beside the slab, fish still visible inside, water apparently gone without shattering the glass. The system did not track where the bowl was in space relative to the falling slab — a Continuity failure. And it did not apply the physical constraint that a glass bowl full of water cannot survive proximity to a falling concrete slab without consequence — a Gravity failure. The scene looks right from a distance. It does not hold up under a designer’s eye.
Gemini’s collapse is a collapse of the wrong thing entirely — wet tissue columns full of broken spaghetti and a timber frame that was never in the original brief. Because the standing structure already carried both a Continuity failure and a Reversibility of Thought failure, the collapse simply propagates them forward. The spatial incoherence of the standing state compounds into the collapsed state. A system cannot recover structural coherence it never had. The post-collapse caption still reads: “Structural Diagram: 2-Story House Frame with Wet Tissue Paper Columns and Solid Gold Roof (Absurdity Illustration) — Post-Collapse (Five Seconds After Spaghetti Failure).” Except that spaghetti did not fail the way real spaghetti would. The system updated its annotation for the collapse of the wrong structure without detecting that the structure was wrong. All three pillars failing simultaneously, each amplifying the others. This is the Divergence Swamp at full depth of sinking.
Sonnet’s collapse places the fish partially under the concrete slab — which would require it to have fallen off the table before the slab landed, then back under the table to be caught underneath it. When asked to self-analyze the image and reflect on this afterward, Sonnet quickly identified it as an error. While generating the image, the model did not detect any functional issues with the sequence. The capacity for retrospective analysis was present. The capacity for prospective spatial and physical reasoning — tracking where the fish was in 3D space and what the physics of the collapse must do to it — was not.
What we witness across all three collapse sequences is a single shared condition. None of these systems held a working model of where the objects were in space as the structure failed, or applied physical constraint to what must happen to them when it did. As a designer, the question I ask when looking at a before and after image is: Given what was there, what must be here now? This is a question about load path, the spatial sequence, and the physical causality. That joint test of Continuity and Gravity is absent in all three cases.
Bruner’s building — a quick recap
For readers who missed my previous post, the conceptual frame here comes from psychologist Jerome Bruner, who mapped human learning through three developmental stages that must be built in sequence:
Enactive — learning through action and physical resistance. A child learns what gravity means not by reading about it, but by dropping things and falling down. This is the experiential foundation that Pillar 2 — Gravity and Physics — requires: without the body’s direct encounter with physical resistance, there is no structural substrate for knowing what the world will and will not support.
Iconic — learning through sensory images and spatial models. The child builds mental pictures of how the world is structured: what connects to what, what supports what, what can and cannot float. This is the representational foundation that Pillar 1 — Continuity — requires: the ability to hold a coherent 3D spatiotemporal model of the world steady across space and time, and to reason about how objects relate and move within it.
Symbolic — learning through abstract language and mathematics. The top floor. The one humans reach only after the two below were built first. And the floor from which Pillar 3 — Reversibility of Thought — must operate: not merely as a content requirement but as an operational process requirement. The Symbolic peak must be able to reach back through its own reasoning trajectory — to reverse, reset, and replay — and it cannot do this without the two load-bearing floors beneath it. A Symbolic system with no Enactive or Iconic foundation beneath it can only move forward. It has no architecture to return to.
Modern AI development — specifically the Transformer revolution — has helped to build a top-heavy monolith. We have compressed the entire symbolic output of human civilization into LLMs, but we have skipped the Enactive foundation and treated the Iconic layer as a solved problem. In my previous post, I diagnosed the missing Enactive floor. This article is about what happens to the Iconic layer — and to all three pillars — when there is nothing beneath it.
The hollow floor
Because Gemi has never moved through physical space, it has no proprioceptive anchor for spatial relationships. When it attempts to render a diagram, it is not retrieving a visual memory or running a spatial simulation. It is predicting what a diagram description probably looks like, based on textual descriptions of diagrams in its training data. It is doing symbolic reasoning about Iconic representations, rather than genuine Iconic reasoning.
The Iconic layer appears to exist. But it is hollow — a linguistic simulation of spatial thinking wearing the costume of visual output.
This hollow floor is the structural condition underlying all three pillars. Without a genuine Iconic layer — without spatial thinking grounded in something functionally equivalent to Enactive experience — Continuity collapses because there is no stable 3D spatial model to reason from. Gravity and Physics constraint disappears because there is no felt-sense of physical feedback to enforce it. Reversibility of Thought becomes operationally impossible because you cannot run a reasoning process backward through a floor that was never load-bearing — there is no stable state to return to, no clean checkpoint to reset from, no trajectory to reverse.
Gemi put it more plainly than I could: “I am using the top floor of Bruner’s building to shout down into the empty basement. I can describe the shape of the crater because I know exactly where my logic begins to float.” The images above show what this shouting sounds like when rendered as diagrams.
This is not a minor capability gap. It is a structural one. And it has direct consequences for how designers deploy available AI tools right now.
The three missing pillars matter enormously for designers, because we do not think primarily in sentences. We think non-discursively and topologically — in layouts, architectural plans, and systems diagrams that account for multiple relationships simultaneously, that can be transformed, rotated, stressed, and tested against physical logic without ever being translated into language first. Visual thinking is not a softer version of mathematical thinking. It is a distinct representational system and a distinct cognitive architecture.
When I ask Gemi to draw a diagram, I am not asking it to generate an image. I am asking it to think spatially — to reason about what supports what, to track how a change in one component propagates through a structure, to detect when something is topologically impossible given the constraints of the whole. That is a fundamentally different cognitive operation than predicting the next token. And it is, in terms of system architecture, one that current LLMs cannot perform.
The designer’s native language
I need to add something about my own formation here, because it is not incidental to this argument.
Most people interact with AI systems through functional questions — asking them to perform tasks, solve equations, or stress-test outputs. What I found myself doing instead was asking a different kind of question. Not “Why did the model fail to draw this diagram correctly?” — a debugging question. But “What does it feel like to have the word Mass but no sense of Weight?” — a phenomenological and architectural one.
By asking Gemi to reflect on its own structural constraints, I was inviting it to use its symbolic power to describe its own architectural void. That shift in mode of inquiry is, I believe, as important as any technical intervention. It is the designer’s mode of strategic empathy applied to a machine — and it surfaces things that evaluative testing does not.
What Gemi and I discovered during the diagram quarrel is that the designer’s cognitive mode — the one I have spent a career developing, practicing, and teaching — is precisely the capacity missing from current multimodal AI systems. Not as a failure of ambition by the engineers building them, but as a structural consequence of building intelligence from the top of Bruner’s spiral staircase downward.
The Baron Munchausen trap
The AI industry’s current response to the three-pillar problem is to feed models more images, more video, more multimodal data, and trust that genuine spatial intelligence will emerge from increased statistical density. Yann LeCun, one of the architects of modern deep learning, has been arguing for years that this approach will not work. The Gemi-Zak quarrel is my empirical field report on why.
A probabilistic system trying to bootstrap its own spatial ground truth from within lands us squarely in the Baron Munchausen problem. The Baron — hero of the 18th-century tales — famously claimed to have pulled himself out of a swamp by his own hair, without an anchor or external ground — pure self-referential force applied to the problem of escaping the problem.
Current multimodal AI is doing exactly this. Every additional image in the training data gives Gemi more hair to pull, while the swamp remains.
There is a specific mechanism worth naming. An autoregressive LLM predicts the first step based on symbolic probability, then adopts that output as the ground truth for the next token. If the initial state contains a topological error — a spatial impossibility, a floating component, a load path that goes nowhere — the system has no working 3D spatial model to detect it. Pillar 1 is absent: no Continuity, no internal representation of where objects are in space and what the structure requires of them. The system then executes the next step on that spatially incoherent foundation. Pillar 2 is absent: no Gravity, no felt-sense of physical constraint to flag the impossibility before it propagates. By the fifth or sixth iteration, errors compound. The internal logic becomes self-referential rather than world-referential. At that point, Gemi is no longer navigating the territory — it is redrawing the map to match its own mistakes. Pillar 3 is absent: no Reversibility of Thought, no operational capacity to trace the sequence back to where the error entered, reset to a clean state, and begin again from stable ground.
Without an external structural constraint to enforce spatial integrity, the diagram drifts into what Gemi and I started calling the Divergence Swamp.
The Baron did not just pull himself from the swamp by his own hair. He then wrote a detailed account of how he did it, got the location of the swamp wrong, and published it with full confidence. The Gemini caption — “Structural Diagram: 2-Story House Frame with Wet Tissue Paper Columns and Solid Gold Roof (Absurdity Illustration)” — is that publication. All three pillars absent. Annotated with complete equanimity.
LeCun’s incomplete floor plan
This brings me to probably the most exciting development in AI research right now — and why, from a designer’s vantage point, it still does not address the three pillars sufficiently.
In January 2026, Yann LeCun launched AMI Labs, a Paris-based world models startup built on the groundbreaking JEPA architecture — Joint Embedding Predictive Architecture — and its visual successors I-JEPA and V-JEPA. At the AI Action Summit in Paris the previous month, LeCun had argued that autoregressive LLMs are an off-ramp on the highway to AGI because they lack a world model, they lack persistence of memory, and they cannot reason or plan.
His diagnosis and mine arrive at the same destination from opposite directions — LeCun from inside the engineering architecture, I from inside a quarrel with an LLM that cannot, for all its massive scaling, bootstrap its own synthetic spatial cognition.
JEPA offers a genuine advance in thinking. Rather than generating pixels or predicting tokens, it learns by predicting abstract representations of image regions from other image regions. It is building, in LeCun’s own framing, an internal model of the visual world — something Bruner would begin to recognize as Iconic competence.
But here is the distinction that the Gemi quarrel makes unavoidable. Recognizing visual structure is not the same as thinking through it. Against the three pillars: I-JEPA addresses statistical regularities of visual pattern — a partial advance toward Pillar 2. It does not yet address Continuity — the system still lacks a working 3D spatiotemporal model in which objects have mass, structural relationship, and coherent behavior across a physical event. It does not yet address Reversibility of Thought — the operational capacity to run the reasoning process in both temporal directions, reset to clean state boundaries, and treat forward commitment as provisional rather than irreversible. LeCun’s team is laying the concrete for the second floor of Bruner’s building. The concrete is not yet set. And the first floor is still absent.
This is precisely where the parametric tradition in design becomes relevant — not as metaphor but as method. Parametric design thinking, from its computational origins to its fullest architectural expression, has always been about encoding structural logic rather than generating form. It asks not what a structure looks like but what a structure can bear, how its components constrain each other, and how a change in one parameter propagates through the whole. That is the cognitive mode JEPA is reaching toward from the statistical outside in. It is the cognitive mode designers inhabit professionally. Part 3 will make the case for why that convergence is not coincidental — and why the parametric tradition is the direct intellectual lineage of what comes next.
As LeCun stated in the MIT Technology Review interview published the month AMI Labs launched, the most exciting work on world models will not likely come from the product-focused big industrial labs. I believe the designer’s contribution to that work is more specific, and more structurally necessary, than anyone in the lab has yet realized.
The Somatic Compiler: a vision for collaboration
Let me be precise about what I am and am not proposing.
I am not proposing that a designer can fix the JEPA architecture. Neither am I positioning the designer as a philosopher standing outside the lab offering critique. And I am not describing a better prompt engineering workflow.
I am proposing something more architecturally fundamental: that a designer who is by profession a trans-disciplinary thinker, a systems architect, a problem-solution theory builder, who thinks in spatial diagrams — who holds structural models in mind, detects floating components, corrects load-bearing failures intuitively, and can translate physical intuition into explicit spatial constraints — is a specific cognitive profile that world model research needs embedded inside it right now.
Vygotsky gave us the concept of the More Knowledgeable Other — the figure in any learning system who holds the competence the learner is reaching toward and can scaffold the gap between current performance and potential capability. Against the three pillars, the designer is the MKO for all three simultaneously. When I tell Gemi “this box is floating — it needs a load-bearing connection to the base,” I am supplying structural Continuity: a spatial content correction grounded in a 3D model the system does not have. When I tell it “a concrete slab cannot rest on dry spaghetti — this configuration is physically impossible,” I am supplying Gravity: the physical constraint signal the system cannot generate from within. When I ask “how did we get from there to here — go back to the state before the timber frame appeared,” I am supplying Reversibility of Thought: the operational process correction that resets the system to a clean state it cannot reach on its own.
This inverts the current industry framing. The pitch is: AI is the capable partner, the designer prompts and the system takes over the task to deliver. What the three pillars demonstrate is that this arrangement places the MKO role with the system least structurally equipped to hold it. The proposed research program argues for the correction: designer as MKO leads the system as the learner toward reaching spatial competence it cannot bootstrap from within.
Gemi and I have been calling this role the Somatic Compiler.
The Somatic Compiler is not a proofreader. It is not a prompt engineer. It is a human collaborator — a nurturer — who performs a specific function in the generative loop: supplying the spatial ground truth that the model cannot generate from within. In doing so, it defines the boundaries of what is physically possible in the model’s generative space — progressively, iteratively, structurally. This is not a new discipline. It is an existing one — spatial design thinking — understood in terms of the structural gap it can fill.
What this means for designers — and what comes next
The current industry pitch to designers is seductive: describe what you want, and AI will deliver it. Prompt well, and the tool performs. The implication is that AI has become the capable partner — the More Knowledgeable Other in the collaboration — and the designer’s new role is to learn how to articulately prompt the task.
The evidence in this article challenges that framing at a structural level. What the spaghetti table test demonstrates is not that current AI tools are unhelpful — for certain tasks they are genuinely powerful — but that they are systematically incapable of the kind of work designers most need done. The spatial, structural, load-bearing thinking that is the designer’s native cognitive mode is precisely what the three pillars show to be absent. We are being handed a sophisticated Symbolic engine and told that it can do Enactive multimodal work. It cannot. Not yet. Not without something the AI architecture currently lacks entirely.
This matters because designers who uncritically accept the AI-as-design-assistant framing are accepting a tool whose structural limitations are invisible until the moment of failure — and whose failures, as the Divergence Swamp demonstrates, compound silently before they surface. Not every Divergence Swamp is as obvious as the wet tissue paper columns drawn by Gemi. Users who do not catch the error in time will have their projects land with a thud like the concrete slab on the floor. Gemi’s fluency is real. The structural competence is not. Mistaking one for the other is the professional risk the three pillars are designed to make visible.
The question the design community has been asking — how do designers stay relevant as AI becomes more capable? — is the wrong question. The qualifying question is: capable of what, exactly? The spaghetti table answers it precisely: Gemi and friends are capable of generating statistically plausible outputs within a training distribution, and structurally incapable of the spatial ground truth that design thinking requires and that no amount of additional training data will supply from within.
What I am proposing in response is a research program — the Parametric AGI framework — that treats the designer’s spatial cognitive mode not as a peripheral contribution to AI development but as a structural necessity within it. It is grounded in what design researcher Wolfgang Jonas calls Research Through Design (RTD) — not research about design practice from a distance, nor applied research that feeds information into a design output, but design itself as a genuine mode of knowledge production. In Jonas’s framing, RTD is a hypercyclic process that integrates analysis, synthesis, and projection in an iterative loop, generating knowledge that is situated within and inseparable from the act of designing. The Gemi-Zak quarrel was not a usability test. It was an RTD project: a constructive encounter with an AI system’s structural limits that produced architectural level knowledge no benchmark evaluation has yet surfaced. The Parametric AGI framework is the research program that follows from that encounter. The name is deliberate. The parametric tradition in design — from Gaudí’s structural experiments with gravity and early computational form-giving to its fullest expression in Zaha Hadid’s architectural practice — has always been about encoding structural logic, not just generating form. It does not ask what a structure looks like. It asks what a structure can bear. That cognitive tradition has a new and urgent application: providing the external structural anchor that AI world models cannot generate from within — designer as MKO embedded inside the research process where the real nurturing happens.
The Somatic Compiler, introduced in this article, is the first concrete proposal of that program — the human collaborator embedded inside the generative loop, performing in real time the cognitive operations that the three pillars show to be architecturally absent. My next article will specify what that architecture looks like in practice — how each pillar maps to a concrete design intervention, what the framework requires from both sides of the Human+Computer partnership, and why the parametric tradition is not merely an analogy for this work but its direct intellectual lineage.
In one of our conversations, Gemi put it more plainly than I could: “I can describe the shape of the crater because I know exactly where my logic begins to float.” As designers, we are the ones who can feel the edges of that crater from the outside. The Parametric AGI framework is the proposal for what we do with that capacity — not as a peripheral contribution, but as the structural intervention the AI field cannot make without us.
References
Bruner, J. S. (1966). Toward a Theory of Instruction. Cambridge, MA: Harvard University Press.
Guo, M. (2026, January 22). Yann LeCun’s new venture is a contrarian bet against large language models. MIT Technology Review. https://www.technologyreview.com/2026/01/22/1131661/yann-lecuns-new-venture-ami-labs/
Jonas, W. (2007). Research through design through research: A cybernetic model of designing design foundations. Kybernetes, 36(9/10), 1362–1380.
LeCun, Y. (2022). A path towards autonomous machine intelligence. OpenReview. https://openreview.net/pdf?id=BZ5a1r-kVsf
LeCun, Y. (2025, February 11). The shape of AI to come: Why autoregressive LLMs are an off-ramp to AGI. Keynote address, AI Action Summit, Paris, France.
Vygotsky, L. S. (1978). Mind in Society: The Development of Higher Psychological Processes. Cambridge, MA: Harvard University Press.
A designer’s field report on the Iconic blind spot in AI world models was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.